学习二分类问题的模型,熟悉逻辑损失函数、pandas.DataFrame()的基础应用。本博文主要用于整理个人的知识框架,希望也能帮到大家。如有不足,欢迎留言。🙏
Pytorch分类任务 运行环境:https://colab.google/
数据准备 准备数据集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from sklearn.datasets import make_circles""" make_circles 是 scikit-learn 库中的 sklearn.datasets 模块中的一个函数。 它用于生成一个带有圆形决策边界的玩具数据集。这个函数对于测试和可视化处理非线性可分数据的算法非常有用。 """ n_samples = 1000 X, y =make_circles(n_samples, noise = 0.03 , random_state = 666 ) X.shape, y.shape type (X), type (y)--> (numpy.ndarray, numpy.ndarray) import torchX = torch.from_numpy(X) y = torch.from_numpy(y) X = X.type (torch.float ) y = y.type (torch.float ) """ 在将 NumPy 数组转换为 PyTorch 张量时,如果没有指定数据类型,PyTorch 将会使用与原始数组相同的数据类型。因此,如果原始的 NumPy 数组中的数据类型是 float32 或 float64,那么转换后的 PyTorch 张量的数据类型也会是相应的 torch.float32 或 torch.float64。 我们需要明确指定数据类型,以确保数据类型与模型和计算设备(如 GPU)的要求相匹配 torch.float 实际上是 torch.float32 的别名。 使用 32 位的内存空间来表示浮点数,具有较高的计算性能,通常在深度学习中被广泛使用。 """
划分数据集 1 2 3 4 from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2 , random_state = 666 )
可视化 pandas.DataFrame 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pandas as pd circles = pd.DataFrame({"X1" :X[:,0 ], "X2" :X[:,1 ], "label" :y}) """ DataFrame 是 Pandas 中最重要的数据结构之一,它类似于电子表格或数据库表格。 DataFrame 是一个二维标记数据结构,可以容纳多种类型的数据,并且每一列都可以有不同的数据类型。 DataFrame 允许你以一种类似于 SQL 或 Excel 的方式轻松地对数据进行操作、筛选、分组和汇总。 X[:,0] 表示取 X 中所有行的第一个特征,即将所有样本的第一个特征存储到 X1 列中。 X[:,1] 表示取 X 中所有行的第二个特征,即将所有样本的第二个特征存储到 X2 列中。 y 则表示样本的标签,将其存储到 label 列中。 最终生成的 DataFrame circles 包含了两个特征列 X1 和 X2,以及一个标签列 label,用来存储每个样本的特征和标签信息。 """ circles.head(10 ) -->如下表
index
X1
X2
label
0
0.5232532787040866
0.6130051138010815
1
1
0.5590261056027346
-0.7938079756641505
0
2
0.07279950491964153
1.0158009611913412
0
3
0.643975455169496
0.4792458217715751
1
4
0.7277505858717157
-0.3306116318780561
1
5
0.8114212398289349
-0.5947803838171337
0
6
-0.9228566785254152
-0.31323880736337917
0
7
0.8211164440168314
-0.52126486439117
0
8
-0.862636456661466
0.052975218510684215
1
9
-0.7868902607268425
0.10441672781411158
1
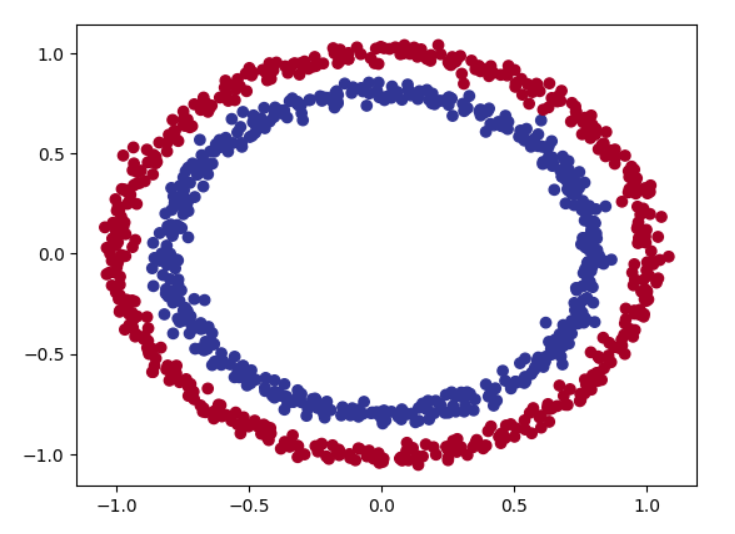
matplotlib.pyplot 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import matplotlib.pyplot as pltplt.scatter(x = X[:,0 ], y = X[:,1 ], c = y, cmap = plt.cm.RdYlBu) """ 这段代码使用 Matplotlib 库创建了一个散点图, 其中 x 轴表示数据集中的第一个特征(X1), y 轴表示数据集中的第二个特征(X2),并根据标签(y)对点的颜色进行着色。 plt.scatter() 函数用于创建散点图。 x = X[:,0] 指定 x 轴的值为数据集中所有样本的第一个特征。 y = X[:,1] 指定 y 轴的值为数据集中所有样本的第二个特征。 c = y 指定散点的颜色根据标签 y 的值来确定。注意,此处的y表示label的y,而不是数据集的第二个特征 cmap = plt.cm.RdYlBu 指定了使用的颜色映射,这里使用了红黄蓝的颜色映射。 """
建立模型 模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchfrom torch import nndevice = "cuda" if torch.cuda.is_available() else "cpu" class CircleModelV0 (nn.Module): def __init__ (self ): super ().__init__() self.layer_1 = nn.Linear(in_features = 2 , out_features = 5 ) self.layer_2 = nn.Linear(in_features = 5 , out_features = 1 ) self.relu = nn.ReLU() def forward (self, x ): return self.layer_2(self.relu(self.layer_1(x)))
声明模型对象 1 model_0 = CircleModelV0().to(device)
分类函数的损失函数如何来定 思考:如何把预测值映射为 0 还是 1?
使用sigmoid函数,然后将 1 / (1 + e^-x) 与0.5来比,使用torch.round()函数四舍五入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 """ Logistic回归是一种用于解决二分类问题的线性模型,通常用于估计样本属于某一类的概率。 Logistic回归可以被视为一个单层的神经网络,其输出通过一个sigmoid函数进行转换,将线性变换的结果压缩到 (0, 1) 区间,表示样本属于某一类的概率。 在PyTorch中,可以使用 nn.Linear 创建一个全连接层,然后通过 nn.Sigmoid 激活函数将线性变换的结果转换为 (0, 1) 区间的概率值。 这样的组合通常被称为Logistic回归层,用于二分类问题的预测。 例如,在PyTorch中,可以如下定义一个简单的Logistic回归层: import torch import torch.nn as nn class LogisticRegression(nn.Module): def __init__(self, input_dim): super(LogisticRegression, self).__init__() self.linear = nn.Linear(input_dim, 1) self.sigmoid = nn.Sigmoid() def forward(self, x): out = self.linear(x) out = self.sigmoid(out) return out """ loss_fn = torch.nn.BCEWithLogitsLoss() """ torch.nn.BCEWithLogitsLoss()这个损失函数结合了 Sigmoid 激活函数和二元交叉熵损失函数,同时计算了两者的结果 使用 BCEWithLogitsLoss 可以简化代码,提高计算效率,尤其适用于二分类问题。 import torch import torch.nn as nn # 创建模型 model = YourModel() # 定义损失函数 criterion = nn.BCEWithLogitsLoss() # 假设预测结果和真实标签已经准备好 outputs = model(inputs) loss = criterion(outputs, targets) # 清零梯度 optimizer.zero_grad() # 反向传播 loss.backward() # 更新参数 optimizer.step() """ optimizer = torch.optim.SGD(params = model_0.parameters(), lr = 1 )
辅助观察函数声明 1 2 3 4 5 6 7 def accuracy_fn (y_true, y_pred ): correct = torch.sum (y_true == y_pred).item() acc = correct / len (y_true) * 100 return acc
训练模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 torch.manual_seed(666 ) epochs = 185 X_train, y_train = X_train.to(device), y_train.to(device) X_test, y_test = X_test.to(device), y_test.to(device) for epoch in range (epochs): model_0.train() y_logits = model_0(X_train).squeeze() y_pred = torch.round (torch.sigmoid(y_logits)) loss = loss_fn(y_logits, y_train) acc = accuracy_fn(y_train, y_pred) optimizer.zero_grad() loss.backward() optimizer.step() model_0.eval () with torch.inference_mode(): test_logits = model_0(X_test).squeeze() test_pred = torch.round (torch.sigmoid(test_logits)) test_loss = loss_fn(test_logits, y_test) test_acc = accuracy_fn(y_test, test_pred) print (f"{epoch} | Loss:{loss} | acc:{acc} | Test Loss:{test_loss} | Test Acc:{test_acc} " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 --> ... 168 | Loss:0.5972417593002319 | acc:72.125 | Test Loss:0.601545512676239 | Test Acc:71.5 169 | Loss:0.595664918422699 | acc:72.5 | Test Loss:0.6001173257827759 | Test Acc:73.0 170 | Loss:0.5940487384796143 | acc:73.0 | Test Loss:0.5980546474456787 | Test Acc:72.5 171 | Loss:0.5923799276351929 | acc:73.5 | Test Loss:0.5966604948043823 | Test Acc:73.0 172 | Loss:0.5906763076782227 | acc:74.0 | Test Loss:0.5944149494171143 | Test Acc:74.0 173 | Loss:0.5889647006988525 | acc:74.375 | Test Loss:0.593086302280426 | Test Acc:75.0 174 | Loss:0.5872295498847961 | acc:74.375 | Test Loss:0.5907705426216125 | Test Acc:74.0 175 | Loss:0.5854421854019165 | acc:74.625 | Test Loss:0.5894856452941895 | Test Acc:76.0 176 | Loss:0.5837037563323975 | acc:75.875 | Test Loss:0.5870495438575745 | Test Acc:75.5 177 | Loss:0.5819454789161682 | acc:75.25 | Test Loss:0.5859463214874268 | Test Acc:76.5 178 | Loss:0.580162763595581 | acc:76.25 | Test Loss:0.5832081437110901 | Test Acc:76.0 179 | Loss:0.5783393979072571 | acc:76.375 | Test Loss:0.5823167562484741 | Test Acc:77.5 180 | Loss:0.5764892101287842 | acc:77.625 | Test Loss:0.5792547464370728 | Test Acc:77.0 181 | Loss:0.5746139883995056 | acc:76.75 | Test Loss:0.5787341594696045 | Test Acc:77.5 182 | Loss:0.5727413296699524 | acc:78.5 | Test Loss:0.5753249526023865 | Test Acc:77.0 183 | Loss:0.5708712339401245 | acc:77.25 | Test Loss:0.5753326416015625 | Test Acc:80.5 184 | Loss:0.5689650177955627 | acc:81.875 | Test Loss:0.5713624954223633 | Test Acc:80.0 ...